Implementations of the table data structure
Collision likelihoods and load factors for hash tables
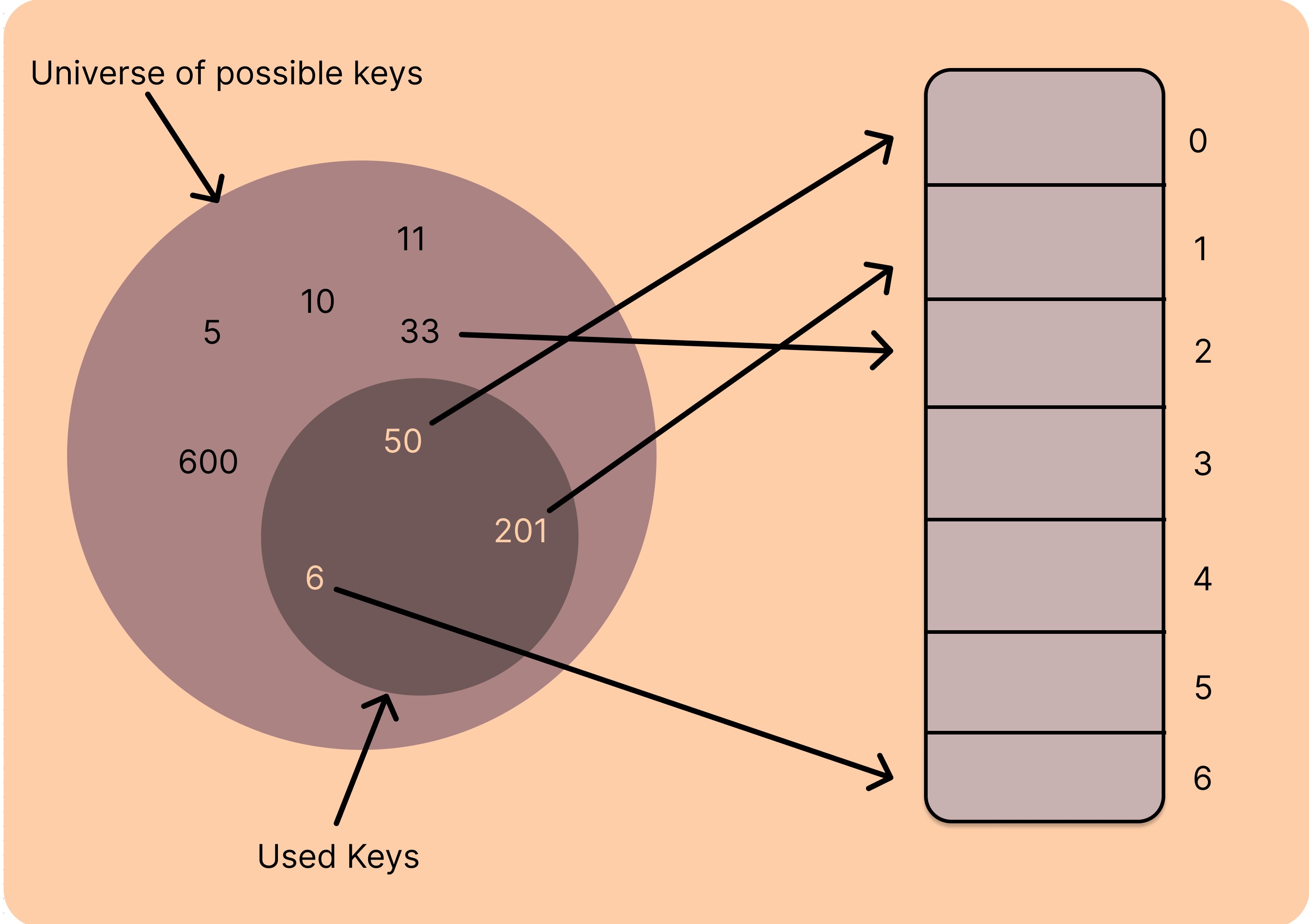
A simple Hash Table in operation
imagine a Library Catalog:
Think of a library catalog as a real-world analogy to a hash table. In this scenario:
1. Books as Values:
Each book in the library represents a "value" that we want to store information about, like its title, author, and location on the shelf.
2. Book Titles as Keys (Addresses):
The titles of the books serve as the "keys" or "addresses" in our map. They uniquely identify each book.
3. Efficient Retrieval with Hashing:
Now, imagine organizing these books based on their titles, but not in alphabetical order. Instead, you decide to use a special formula or "hash function" to determine the location of each book on the shelf. This ensures efficient retrieval.
The Library Setup:
1. Bucket Array:
Your library shelves are like the "bucket array" in a hash table. Each shelf is a "bucket" that can hold multiple books.
2. Hash Function:
The hash function is your magical way of determining which shelf (bucket) a book belongs to based on its title.
Let's Break Down the Steps:
1. Adding a Book:
When a new book arrives, you use the hash function to quickly figure out which shelf it belongs to. You place it on that shelf. This operation is fast, and it doesn't depend on the total number of books in the library.
2. Finding a Book:
Now, if someone asks for a particular book, you apply the hash function to its title. It tells you exactly which shelf to look on. You go directly to that shelf and find the book. This is also a quick operation.
3. Hash Collisions:
Sometimes, two books might end up with the same hash, leading to a "collision" (multiple books trying to be on the same shelf). In these cases, you can handle it by, for example, having a small additional shelf or rearranging the books slightly.
Benefits:
Speed: The key advantage is speed. Finding a book (value) based on its title (key) is very fast, usually taking O(1) time, thanks to the hash function.
Efficient Use of Space: The library doesn’t need to be organized alphabetically, saving space. Each title directly points to its location.
Dynamic Scaling: As the library grows, you can adjust the number of shelves or improve your hash function to maintain efficiency.
Conclusion:
In summary, a hash table, like our library catalog, is a smart way to organize and retrieve information efficiently. It turns the potentially slow O(n) worst-case scenario into a fast O(1) expected time for most operations, making it a powerful tool in various applications like symbol tables in compilers or registries of environment variables.
Hash function
Introducing "Data Harmony": a brilliant method transforming diverse information into a compact melody within a fixed-size array. This ingenious technique orchestrates seamless storage and swift retrieval, conducting a symphony of efficiency. Say goodbye to data clutter and hello to a harmonious blend of simplicity and performance!
Hash Table
Hash tables, known as hashing, offer speedy insertions, deletions, and finds with constant average time. Unlike binary search trees, they excel at unordered operations but lack efficiency in tasks like finding minimum or maximum values and printing the entire table in sorted order.
Collision
Hash functions assign unique addresses to keys, but collisions occur when multiple keys map to the same address. This means two records end up in the same spot. Creating a perfect hash function is challenging, making collisions inevitable.